I’ve been a fan of powerful handheld devices for a long time. I bought a Palm Pilot to help me keep track of my university classes in the 90’s and graduated up to a Treo earlier this decade. The iPhone is the first device out of all of them that makes mobile publishing a breeze (and fun too).
There were a few attempts at blog and twitter integration on the old Palm platform, but networking always felt like it was bolted onto the OS, rather than an integral part of the experience.
My only beef with Apple’s platform is the low end camera included on these phones (and the lack of video support). From what I’ve read, these two shortcomings may be addresses in the rumoured iPhone revision ramp coming in July.

Read full post
My Typo installation has been busted for a while– I decided I’d bite the bullet and install WordPress. It’s pretty much the defacto standard for self-hosted blogs and it’s flexible enough for my needs.
This is the fourth iteration of my personal blog. My first was a hand-crafted news page of posts (using pico and an AIX shell, nonetheless) before blogs were called blogs.
The second was managed using FogCreek’s CityDesk. CityDesk is a great program for managing simple sites, but its lack of scripting and advanced content management features made it a pain to use. It also took forever to republish my whole site over FTP. I couldn’t tell you if the program has improved since I last used it a few years ago.
My third, as mentioned earlier, used the RoR-based Typo blog engine. It was by far the coolest blog engine at the time, but it ran like crap on my hosted 1&1 website. Not really anyone’s fault, mind you - having to reload the Ruby VM for every page is not a great solution.
Anyways, welcome to my fourth iteration of the blog on grack.com. I hope WordPress is a stable and fast platform. I’ll be updating the theme to be less default-y over the next while, so bear with me.
Read full post
Note to the Google Reader mobile team
permalink
I read all I my feeds through Google Reader. Of all the RSS readers, it is the cleanest and most convenient to use. When I started reading feeds on a mobile device, I was happy to see that the Reader team had put some effort into creating a fantastic mobile experience as well.
There are a couple of minor issues with the product:
- When reading feeds with a large number of unread items, you need to manually select an item to load the next batch of items. I prefer the infinite scrolling style of feed reading, where new items are automatically loaded as you scroll to the bottom. Since the additional items are appended to the list that has already loaded, why not just load these automatically?
- There’s no way to mark a whole tag as read without viewing its stream of aggregated items. There is an option to add a new feed at the tag level, but this is something I do far less often than marking a category as read.
- After I mark a feed (or a whole tag) as read, it would be great if it could bring me back up one level. I’m always going through the actions of “mark as read”, then hitting the back button– I’d love to save a tap here.
Overall, Reader mobile is a great product and I’m glad I have it. I can’t wait until DOM storage or Gears is available on mobile Safari so I can bring all my feeds with me without incurring mobile data use.
Read full post
I’m having trouble getting Feedburner to update from my server, so feeds aren’t showing up in Google Reader. It’s not pulling down the latest posts, just the ones from yesterday and before. Any ideas?
UPDATE: It would help if I didn’t redirect FeedBurner to its own feed.
Read full post
Google's Eclipse plugin for GWT and AppEngine
permalink
We’ve been trying out Google’s Eclipse plugin for the last week and it’s made a huge difference to our GWT development experience. The plugin is designed to enhance your Java AppEngine and GWT workflow. We’re mainly using it for GWT development, so the biggest wins for us are the GWT features, including:
- Auto-completion and error checking for JSNI. JSNI is a powerful, yet horribly complex beast to work with. With the plugin, it becomes almost as simple as working with Java code.
- Automatic management of GWT jar references. This is a big help for cross-platform development, as each platform needs its own, specific jar (gwt-dev-linux, gwt-dev-mac, gwt-dev-windows, etc.).
- Automatic provisioning of run targets with appropriate runtime classpath entries. GWT requires you to ensure all your translatable Java source directories are available on the classpath. Each of the run targets you create is pre-populated with this information from referenced projects, saving you the step of manually managing them (or hacking them into your project’s global classpath).
- Support for running a unit test as a “GWT unit test”. This lets you launch a GWT-enhanced unit test in either hosted or web mode.
- Right-click/run for any module in your GWT project, replacing custom .launch files previously required for each module.
- Wizards to create common GWT components: modules, entry points and GWT-enhanced HTML files.
There’s some cool support for AppEngine in the plugin as well. You can publish a hybrid GWT/AppEngine project to Google’s servers with a couple of clicks. This makes the development/deploy cycle trivial, allowing you to quickly iterate using the same environment as your production applications. With this new toolset, AppEngine is an easier platform to deploy to than servers you own and operate yourself, IMHO.
Aside: one interesting feature that slipped under the radar for this AppEngine release is support for cron-style jobs. While this was possible using a cron job on a managed server hitting a URL on your application instance, implementing it in the platform itself makes life easier for web developers. Note that this isn’t true cron, but rather a “hit this URL on this schedule” feature. I actually prefer having cron jobs exposed as web endpoints - it saves you from having to duplicate your web framework’s infrastructure setup in a command-line application.
All-in-all, a very cool release. Thanks to the GWT and AppEngine teams for making this a reality.
Read full post
There’s a bug in the latest Java 1.6 that Apple provides that gets tickled by the GWT 1.6 compiler. It manifests as a reproducible HotSpot compiler crash that looks like this:
[java] Invalid memory access of location 00000000 rip=01160767
When you look into the crash logs that Java produces (found under ~/Library/Logs/CrashReporter/java_*), you can see that HotSpot was compiling a method when it crashed:
Java VM: Java HotSpot(TM) 64-Bit Server VM (1.6.0_07-b06-57 mixed mode macosx-amd64)
Current thread (0x0000000101843800): JavaThread "CompilerThread1" daemon [_thread_in_native, id=1756672000, stack(0x0000000168a4b000,0x0000000168b4b000)]
Stack: [0x0000000168a4b000,0x0000000168b4b000]
Current CompileTask:
C2:637 org.eclipse.jdt.internal.compiler.lookup.ParameterizedMethodBinding.<init>(Lorg/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding;Lorg/eclipse/jdt/internal/compiler/lookup/MethodBinding;)V (596 bytes)
The workaround is to disable JIT of some JDT methods using some advanced JVM command-line arguments. Using Ant, you can tack them on to your GWT compiler task <java> blocks, like so:
<java classname="com.google.gwt.dev.Compiler" classpathref="compileClassPath@{module}" fork="true" failonerror="true">
...
<jvmarg value="-XX:CompileCommand=exclude,org/eclipse/core/internal/dtree/DataTreeNode,forwardDeltaWith" />
<jvmarg value="-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding,<init>" />
<jvmarg value="-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedMethodBinding,<init>" />
By applying those commands, you ask the HotSpot compiler to skip those methods (relying on the interpreter to run them). You’ll know it’s working if you see this during your compile:
[java] CompilerOracle: exclude org/eclipse/core/internal/dtree/DataTreeNode.forwardDeltaWith
[java] CompilerOracle: exclude org/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding.<init>
[java] CompilerOracle: exclude org/eclipse/jdt/internal/compiler/lookup/ParameterizedMethodBinding.<init>
[java] Compiling module com.dotspots.ExtensionModule
I’m hoping that Apple eventually gets around to releasing an updated Java 1.6 for OSX. This bug was fixed in mainline Java a very long time ago!
Read full post
AppEngine+Java+OSX "Invalid memory access" on deploy
permalink
UPDATE, Apr 19 2009: This does not fix all compiler crashes in Eclipse. This is only useful for the compiler crashes where an Eclipse JVM configuration is used. Please see my later blog post for a better fix and disregard this information.
This is the same error I hit before (see my earlier post), but it happens in Eclipse during the “deploy to AppEngine” phase. You’ll see it if you’ve got a project configured with a 1.6 JVM on the build path (even if your .class compatibility is set to 1.5). It’s not obvious how to fix this at first glance - I had to dig around to find the options that Eclipse passes to the JVM.
The solution
You can fix it by adding the same compiler workarounds we explored before to your JVM default arguments. IMPORTANT NOTE: Add the args to all of your 1.6 level installed JVMs. I’ve found that Eclipse doesn’t always choose the selected one if there’s an equivalent also installed (ie: it may use your ‘1.6’ JVM if you have ‘1.6.0’ selected).
-XX:CompileCommand=exclude,org/eclipse/core/internal/dtree/DataTreeNode,forwardDeltaWith -XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding,<init> -XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedMethodBinding,<init>
Add them to your JVMs under Preferences > Java > Installed JREs by clicking the edit button and filling out “Default VM Arguments”:
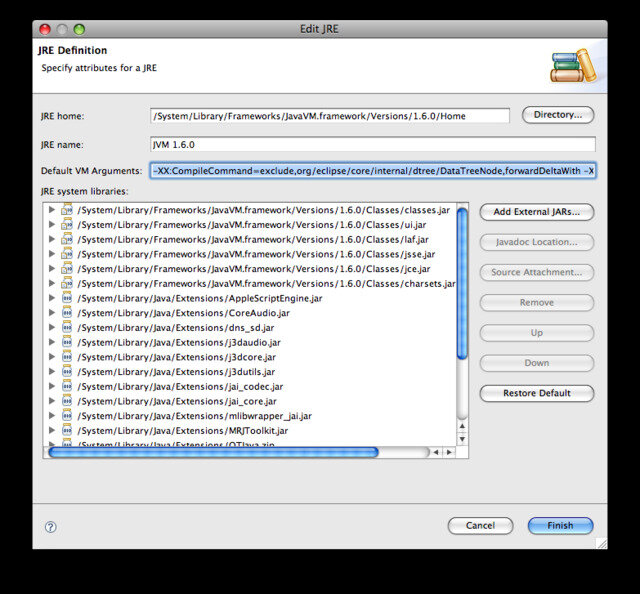
Read full post
The final word on Google Eclipse plugin OSX crashes
permalink
I’ve blogged about the subject of GWT JVM crashes far too much (here and here). This is, I hope, the final word on the subject. I spent some time disassembling the Google Eclipse plugin (did I agree not to do that in one of the EULAs? ;)) and discovered that they are launching the JVM without using the Eclipse infrastructure. This means that the JVM arguments are effectively hardcoded, except in one case where -startOnFirstThread is passed for OSX clients. For those interested, the buggy classes of note are GWTDeploymentParticipant and LaunchUtils.
I posted a note on the contributor’s list and received a response from a Googler suggesting that I wrap my Java executable in a shell script. Not one to shy away from wrapping system executables with scripts, I decided to give it a shot tonight. My first shell script attempt was a disaster, so I gave it a whack in Python.
This is tested and somewhat guaranteed to work for JVM 1.6 under OSX:
cd /System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home/bin
sudo mv java java_wrapped
sudo nano java
And the script:
#!/usr/bin/env python
import sys
import os
print sys.argv
cmd = os.path.dirname(sys.argv[0]) + '/java_wrapped'
args = ['',
'-XX:CompileCommand=exclude,org/eclipse/core/internal/dtree/DataTreeNode,forwardDeltaWith',
'-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding,<init>',
'-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedMethodBinding,<init>']
args.extend(sys.argv[1:])
print cmd
print args
print ""
os.execv(cmd, args)
If you have any suggestions on how to improve my Python, I’d be glad to hear them in the comments.
UPDATE: Thanks to Vitali, I got a bash script working as well:
#!/bin/bash
`dirname $0`/java_wrapped \
"-XX:CompileCommand=exclude,org/eclipse/core/internal/dtree/DataTreeNode,forwardDeltaWith" \
"-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedTypeBinding,<init>" \
"-XX:CompileCommand=exclude,org/eclipse/jdt/internal/compiler/lookup/ParameterizedMethodBinding,<init>" \
"$@"
Read full post
Oracle buys Sun (but really MySQL and Java)
permalink
The news that Oracle bought Sun caught me off guard. I was moderately disappointed when they were courting IBM as a suitor, but I would have been more than happy if they had gone through with the deal. IBM understands open-source and has a proven track record in Eclipse.
The best case scenario for Java would have been a acquisition by or a merger with RedHat, though that would be very unlikely considering the size of RedHat itself - Sun is almost four times bigger than RedHat. Out of some of the big software names large enough to buy and aggregate Sun’s high-end open-source assets, Google would have been a great choice. They have shown a great deal of leadership in the open-source community. We would have seen a vibrant community spring up out of this - consider how well the large GWT open-source projects are run.
So, what does the future hold for Java now? I can’t tell, but the I think the best case is status quo for now. I hope that Oracle spins Java off into its own, independent organization in the future.
If it comes down to it, the community will route around any damage. It started down that path once before with Classpath and Apache Harmony, but those didn’t turn out to be necessary at the time. Who knows - maybe Oracle will change through this whole process? I’m not holding my breath, however.
Read full post
Digg just released a prototype of their optimized data streams. This this is pretty cool. It uses MIME multipart HTTP responses to return a stream of responses, dispatching each one as it comes in. Bugzilla has been using MIME multipart for a while, though only to serve a short “Bugzilla is searching for your bugs” message before returning the actual results.
I’m still digging through it but it looks like a great way to deal with large numbers of resources at pageload time. As an example, you can batch 50 individual profile images in a single HTTP connection roundtrip to populate your frontpage, versus having to serve 50 individual images, or having to manually stitch them into a single image on the server side.
Assuming you can scale it well on the server, you could potentially multiplex a few long-running API calls on a single stream as well. As each one is ready, you could then throw it down the pipe and deal with it on the client.
The concept is cool. There are some limitations obviously, but it’s a fantastic way to deal with bulk data transfer.
More at ReadWriteWeb and Digg the Blog.
Read full post
April showers? Ha! Taken outside my driveway:


Update: getting heavier now, near white-out at times. Another shot from the Apple iBlurryCamPhone:

Read full post




