AppEngine vs. EC2 (an attempt to compare apples to oranges)
This is an expanded version of my answer on Quora to the question “You’ve used both AWS and GAE for startups: do they scale equally well in terms of availability and transaction volume?”:
I’ve had an opportunity to spend time building products in both EC2 (three years at DotSpots and the last year working on Gri.pe). At DotSpots, we started using EC2 in the early days, back when it was just a few services: EC2, S3, SQS and SDB. It grew a great deal in those years, tacking on a number of useful services, some which we used (<3 CloudFront) and a number that we didn’t. Last year, around April, we switched over to building Gri.pe on AppEngine and I’ve come to appreciate how great this platform is and how much more time I spend building product rather than infrastructure. Other developers enjoy building custom infrastructure, but I’m happy to outsource it to Google.
Given these two technologies, it’s difficult to directly compare the them because they are two different beasts: EC2 is a general purpose virtual machine host, while AppEngine is a very sophisticated application host. AppEngine comes with a number of services out-of-the-box. The Amazon Web Services suite tacks on a number of various utilities to EC2 that give you access to structured, query-able storage, automatic scaling at the VM level, monitoring and other goodies too numerous to mention here.
Transaction Volume
When dealing with AppEngine, the limit to your scaling is effectively determined by how well you program to the AppEngine environment. This means that you must be aware of how transactions are processed at the entity group level and make judicious use of the AppEngine memcache service. If you program well against the architecture and best practices of AppEngine, you have the potential of scaling as well as some of Google’s own properties.
Here’s an example of one of the more expensive pages we render at Gri.pe. Our persistence code automatically keeps entities hot in memcache to avoid hitting the datastore more than a few times while rendering a page:
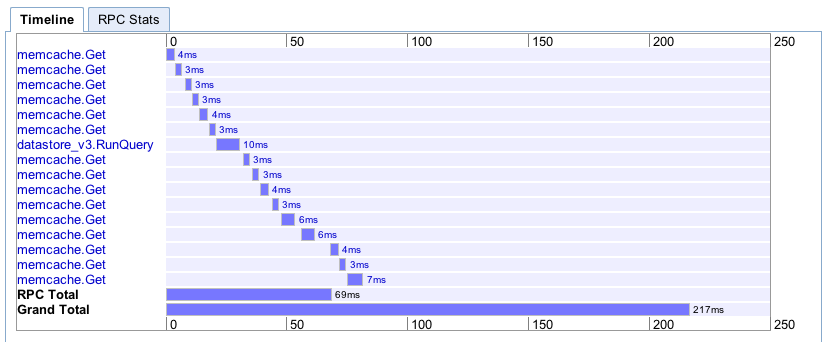
On EC2, scaling is entirely in your hands. If you are a MySQL wizard, you can scale that part of the stack well. Scaling is half limited only by the constraints of the boxes you rent from Amazon behalf by your skill and the other half by creativity in making them perform well. At DotSpots, we spent a fair bit of time scaling MySQL up for our web crawling activities. We built out custom infrastructure for serving key/value data fast. There was infrastructure all over the place just to keep up with what we wanted to do. Our team put a lot of work into it, but at the end of the day, it was fast.
It’s my opinion that your potential for scaling on AppEngine is much higher for a given set of resources, if your application fits within the constraints of the “ideal application set” for AppEngine. There are some upcoming technologies that I’m not allowed to talk about right now that will expand this set of ideal applications for AppEngine dramatically.
Reliability and availability
As for reliability and availability, it’s not an exact comparison here again. On EC2, an instance will fail from time-to-time for no reason. In some cases it’s just a router failure and the instance comes back in a few minutes to a few hours later. Other times, the instance just dies, taking its ephemeral state with it. In our large DotSpots fleet, we’d see a machine lock up or disappear somewhere around once a 1 month or so. The overall failure rate here was pretty low, but enough that you need to keep on your toes for monitoring and backups. We did have a catastrophic failure while using Elastic Block Store that effectively wiped out all of the data we were storing on it - that was the last time we used EBS (in fairness, that was in the early days of EBS and this probably not as likely to happen again).
On AppEngine, availability is a bit of a different story. Up until the new High-replication datastore, you’d be forced to go down every time the Datastore went into maintenance - a few hours a month. With the new HR datastore, this downtime is effectively gone, in exchange for slightly higher transaction processing fees on Datastore operations. These fees are negligible overall and definitely worth the tradeoff for increased reliability.
AppEngine had some rough patches for Datastore reliability around last September, but these have pretty much disappeared for us. Google’s AppEngine team has been working hard behind the scenes to keep it ticking well. There are some mysterious failures in application publishing from time-to-time on AppEngine. They happen for a few minutes to a few hours at a time, then get resolved as someone internally at Google fixes it. These publish failures don’t affect your running code - just your ability to publish new code. We’re doing continuous deployment on AppEngine, so this affects us more than others.
If you measure reliability in terms of the stress imposed on developers keeping the application running, AppEngine is a clear winner in my mind. If you measure it by the time that your application isn’t unavailable from forces beyond your control, EC2 wins (but only by a small amount, and by a much smaller margin when comparing the HR datastore).
Follow me (@mmastrac) on Twitter.