The heartbreak of the pivot
(This was originally a response to a question asked of me on Quora, but I’ve copied it here to my blog so I can expand on it)
“Pivot” is a big catchphrase in the startup world these days. It has a glamorous feel to it: you picture the Twitter team dropping Odeo on the ground and moving on to the brand new idea without a moment’s thought. There’s more to it than that.

In May of 2010 we stopped spending all of our resources on DotSpots and started working on our new idea, Gri.pe. By our September launch at TechCrunch Disrupt, we were focusing all of our efforts on it and decided that we’d start the process of shutting down DotSpots.
Moving on from DotSpots was bittersweet. We spent a few years pouring our heart into the product, which we all honestly believed would revolutionize how people consumed news. Unfortunately we underestimated how difficult it would be to get publishers to sign on and missed the window overall for success.

Another thing that’s hard for me is having the great GWT-based infrastructure we built to pop up UI overtop of any webpage basically sitting idle. I’d love to open-source that one day, but it’s not pressing right now. Perhaps if the right project comes along, we might be able to hand off some of it to them.
We did manage to use some of the DotSpots technology to bootstrap our efforts at Gri.pe. The core web infrastructure for serving Gri.pe pages is basically what we were going to use for serving dotspots.com. I’ll be opening that up at some point in the future at http://stencilproject.net.
The great part about moving on is that you have a chance to let go of all the future plans that were weighing on your mind. After a few years at a startup, you’ve got stuff that you’ve always wanted to do but never had time for. Pivoting to a new idea lets you finally let go of those in your mind.
You also have a chance to make your core technology choices again. At DotSpots, we built everything in Java running Jetty on EC2. At Gri.pe, we’ve chosen to work on AppEngine, which opens up so many exciting possibilities with all of the technology Google is hooking up to it.
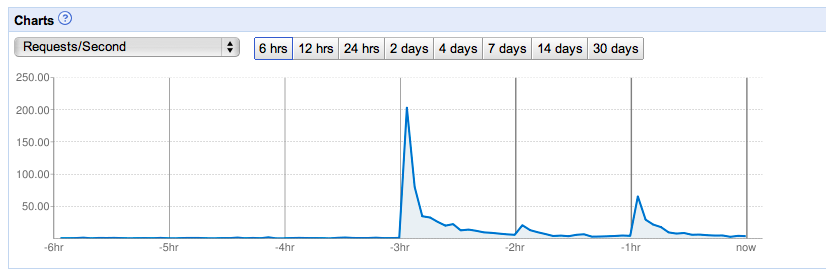
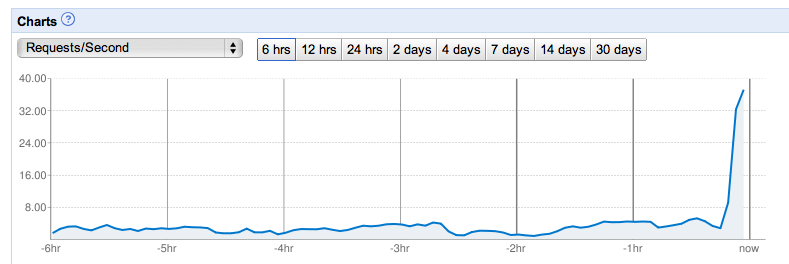
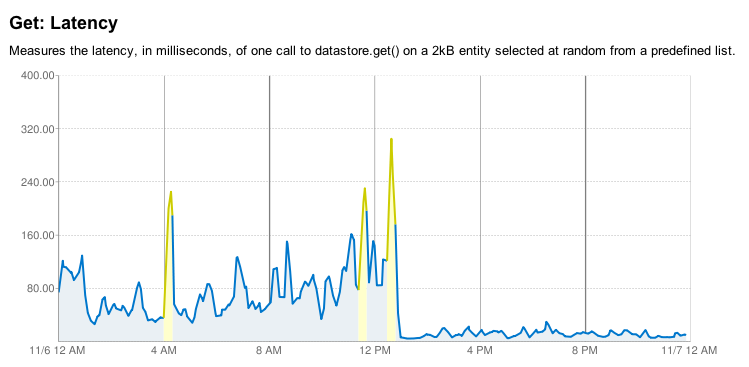
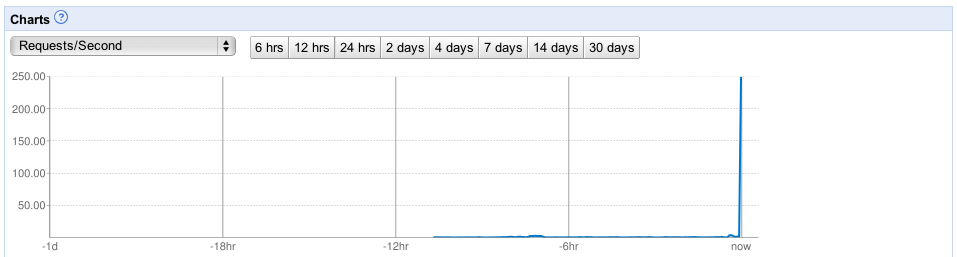
It’s also a great feeling to be working on an application that’s seeing significant traction in the market. We blew by the total lifetime number of users of DotSpots within a few months and continue to great press and a continuous stream of signups. It makes you feel good seeing numbers that show people are using the application and it’s making a positive impact on their lives. I would have loved for DotSpots to have a positive impact too, but it just never caught on.
In the end, it’s an awesome move for us. On the other hand it’s a bit sad - like moving from a house you’ve lived in for years and have built memories in.
Follow me on Twitter: @mmastrac.